
3D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring four novel stand-alone modules that aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next, we construct a contrastive training scheme to induce separation in the latent space, we then resolve view-dependent utterances via a learned global camera token, and finally we employ multi-view ensembling to improve referred mask quality. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark and has won the ICCV 3rd Workshop on Language for 3D Scenes "3D Object Localization" challenge.
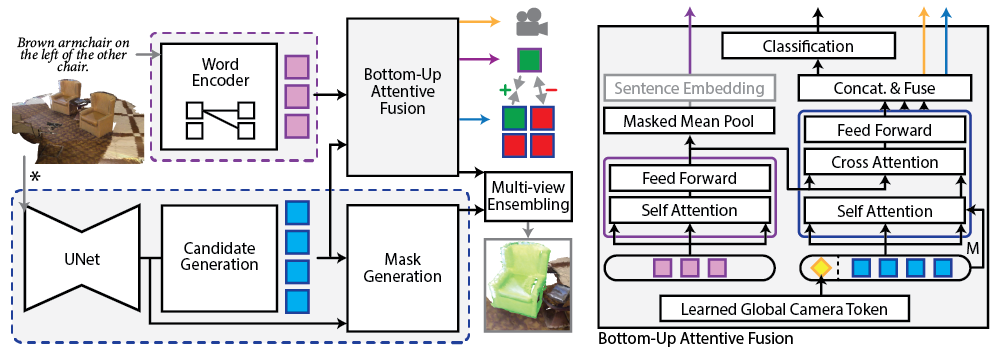
Given a point cloud and a natural language prompt, we first generate instance candidates (blue) and word embeddings (pink). We then fuse these to densely ground the verbal description to the 3D scene. We improve performance by localizing attention via a bottom-up attentive fusion module (right), utilizing contrastive learning to promote better feature separability, and learning the camera position to disambiguate view-dependent descriptions. Our final prediction is generated by merging the token of the best-fitting instance with its predicted mask.
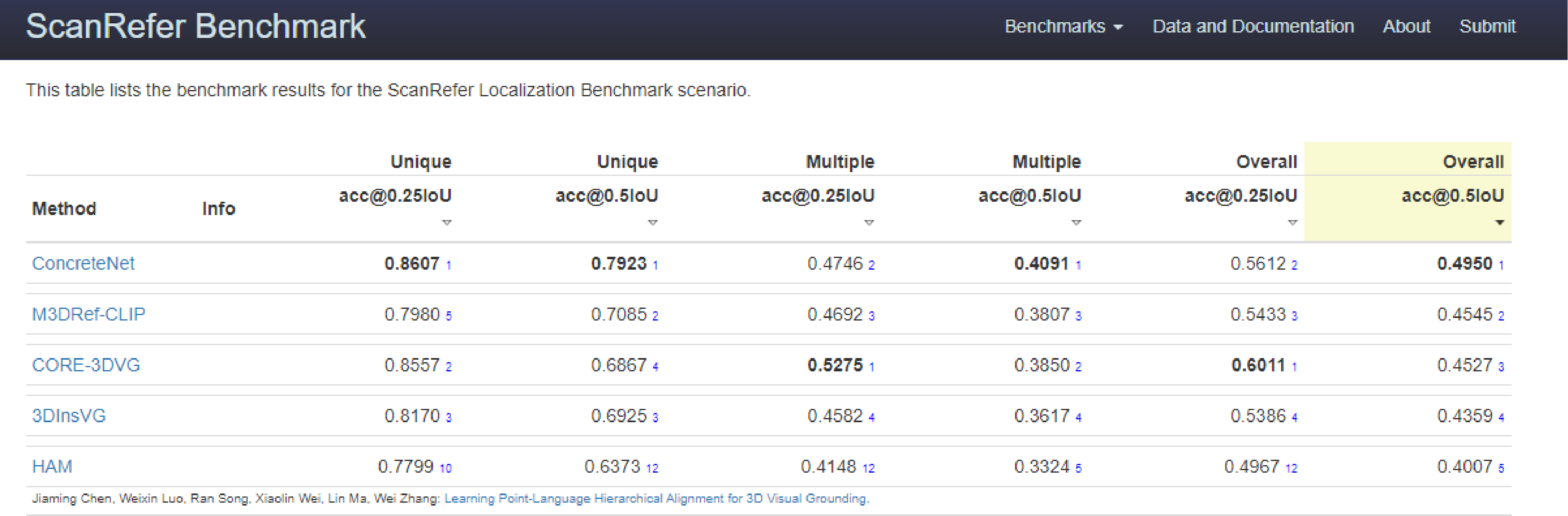
ConcreteNet ranks 1st on the ScanRefer online benchmark and has won the ICCV 2023 3rd Workshop on Language for 3D Scenes "3D Object Localization" challenge!

@InProceedings{unal2024ways,
author = {Unal, Ozan and Sakaridis, Christos and Saha, Suman and Van Gool, Luc},
title = {Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding},
booktitle = {European Conference on Computer Vision (ECCV)},
month = {October},
year = {2024}
}